Pythonで中心極限定理の体験
統計学の入門書には中心極限定理について、「どんな分布の母集団であれ、抽出するサンプルサイズnが大きくなるにつれて標本平均の分布は、平均μ、分散 の正規分布
に近づく。」という記述があります。初めの頃は標本平均の分布って何?という状態であり、今でも正直、標本サイズの話なのか標本数の話なのかよくわかっていないところがあります。そこで実際にPythonを使って確認してみたいと思います。
0. 必要なライブラリの準備
まずは下記ライブラリを準備します。
# 数値計算ライブラリ import numpy as np from scipy import stats # グラフ描画ライブラリ import matplotlib.pyplot as plt %matplotlib inline import japanize_matplotlib
1. 2項分布の乱数シミュレーション
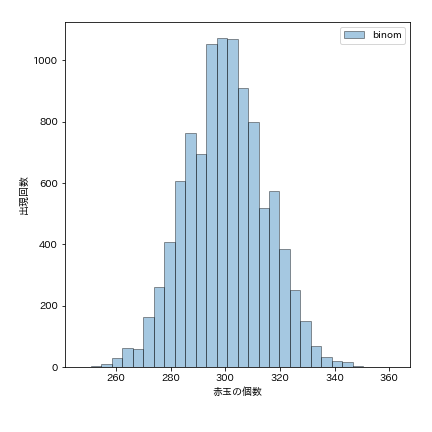
限りなく大きな袋の中に赤玉と白玉が3:7の比率で入っているとします。但しこの比率は神様だけが知っています。この袋の中から一回に1000個の玉を取出し、取出した赤玉の個数を調べます。これを10000回繰返して赤玉の個数の分布を調べます。取出した玉が赤か赤以外かはベルヌーイ分布(成功確率p:0.3)に従い、1000個の玉を取り出すので試行回数n:1000の2項分布になります。
2項分布のライブラリとしてscipyのstats.binom.rvsを用います。
パラメータにn:標本サイズ,p:成功確率,size:繰返し数を設定すると、rvsは2項分布に従ったランダムな成功回数(赤玉の個数)を返します。繰返し数は10000回とします。
vals = stats.binom.rvs(n=n, p=p, size=size, random_state=0)
この成功回数をmatplotlibのヒストグラムを用いて表示します。
とりあえず階級の個数をbins=30として設定
これをグラフ表示させると、下記のように何となく正規分布に近いグラフとなります。
# 例1 2項分布のグラフ n = 1000 #標本サイズ p = 0.3 #成功確率 size = 10000 #繰返し数 # 2項定理 B(n,p)をsize回繰返し、成功回数valsを得る vals = stats.binom.rvs(n=n, p=p, size=size, random_state=0) # グラフ描画 fig = plt.figure(figsize=(6, 6)) #グラフ枠指定,グラフサイズ ax = fig.add_subplot() #グラフ描画指定 plt.hist(vals, alpha=0.4,bins=30, label='binom', density=False, ec='black') #ヒストグラム plt.xlabel('赤玉の個数') plt.ylabel('出現回数') plt.legend() plt.show() # 平均値計算 mean = np.mean(vals) mean_rate = mean/size print(f'平均成功回数:{mean:.4g}') print(f'平均成功率:{mean_rate:.4g}')
2. 正規分布のグラフを重ね合わせてみる
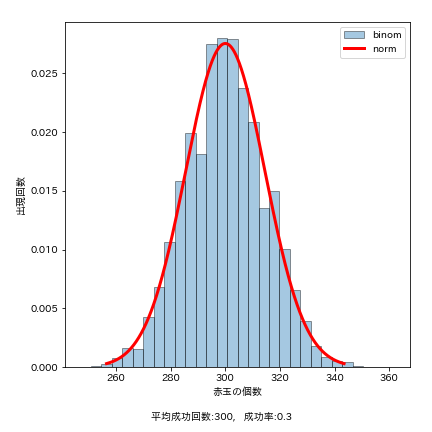
見た目は正規分布のグラフに近いと思うのですが、どれくらい正規分布に近いか正規分布のグラフと重ねてみます。
正規分布を描くにはstats.norm.pdfを使います。
・rvsがランダムな確率分布の度数を返すのに対し、pdfは理論的な確率分布の値を返します。
・norm.pdfでloc:平均, scale:標準偏差を設定します。
・正規分布を求める際に使用する平均と分散は2項分布側の実現値の平均・分散になるので、binom.meanとbinom.varを用いて求めます。
・正規分布でのxの範囲は平均から±3σ点(99.7%)といういうことにしました。
・またグラフのy軸は度数ではなく、確率値にする為、2項分布のplt.histでdensity=Trueに変更します。
2項分布と正規分布のグラフがいい具合に重なったようです。
# 例2 2項分布と正規分布の重ね合わせ n = 1000 #標本サイズ p = 0.3 #成功確率 size = 10000 #繰返し数 # 2項定理 B(n,p)をsize回繰返し、成功回数valsを得る vals = stats.binom.rvs(n=n, p=p, size=size, random_state=0) # グラフ描画 fig = plt.figure(figsize=(6, 6)) #グラフ枠指定,グラフサイズ ax = fig.add_subplot() #グラフ描画指定 plt.hist(vals, alpha=0.4,bins=30, label='binom', density=True, ec='black') #ヒストグラム plt.xlabel('赤玉の個数') plt.ylabel('出現回数') plt.legend() # 平均値計算 mean = np.mean(vals) mean_rate = mean/size ax.text(0.25, -0.15, f'平均成功回数:{mean:.3g}, 成功率:{mean_rate:.3g}', transform=ax.transAxes) #--正規分布のpdfを描画 mu = stats.binom.mean(n, p, loc=0) # 2項分布の平均 var = stats.binom.var(n, p, loc=0) # 2項分布の分散 x = np.arange(mu-3.00*var**0.5, mu+3.00*var**0.5, 0.001) # 99.7%点まで描画 norm_vals = stats.norm.pdf(x, loc=mu, scale=var**0.5) # pdfの値を生成 plt.plot(x, norm_vals, label='norm') plt.legend() plt.show()
3. 標本サイズを変化させる
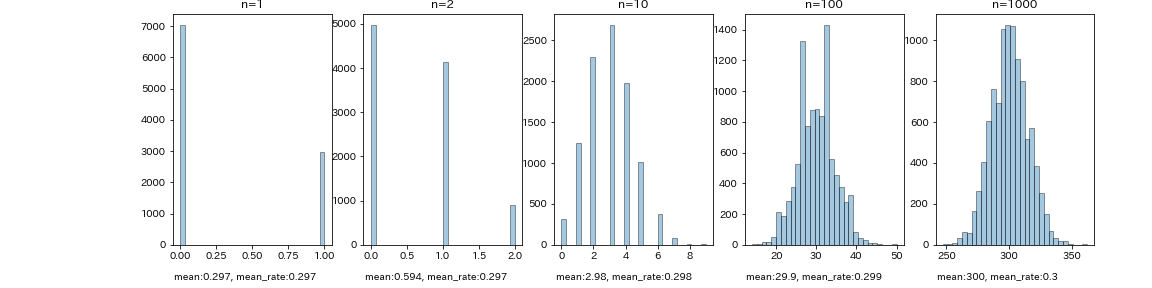
ここで標本サイズの値を色々と変化させてヒストグラムの変化を見ることにします。
標本サイズをn_list = [1, 2, 10, 100, 1000]とリストにしてfor文で5回繰り返します。
fig.add_subplot(1,5, k+1)で1行5列のフレームにk+1番目のグラフを表示させます。
またplt.title(f'n={n}')としてグラフタイトル欄に標本サイズを表示させます。
標本サイズが増えるにつれて、正規分布の形に近づいているようです。
# 2項分布の標本サイズを変化させる #2項分布B(n,p)のパラメータ n_list = [1, 2, 10, 100, 1000] #標本サイズ size = 10000 #繰返し数 p = 0.3 #成功確率 fig = plt.figure(figsize=(16, 4)) for k, n in enumerate(n_list): # 2項定理 B(n,p)の試行をsize回繰返す vals = stats.binom.rvs(n=n, p=p, size=size, random_state=0) # 2項分布の標本平均の分布をヒストグラムとして描画 ax = fig.add_subplot(1,5, k+1) #1行5列のグラフ枠のk+1番目に描画 plt.hist(vals, alpha=0.4, label='binom', bins=30, density=False, ec='black') plt.title(f'n={n}') #グラフタイトルに標本サイズを表示 #平均値計算 mean = np.mean(vals) mean_rate = mean/n ax.text(0.01, -0.15, f'mean:{mean:.3g}, mean_rate:{mean_rate:.3g}', transform=ax.transAxes)